AWS CDKでLambdaのサンプルを作る
はじめに
個人的に必要だったツールを開発した際にCDKを使ったので、手順などを含めて忘れないようにサンプルと共にまとめておく。
サンプルはCDK Workshopと同じ内容で、API GatewayとLambdaを使ってHello, CDK!という文字列を返すアプリ。
https://github.com/tkt182/cdk_lambda_sample
やったこと
ちなみに、LambdaはRubyで書いています(普段Rubyを使っているので)。
開発環境構築
1. Node.jsインストール
nodenv経由でinstallする。
https://github.com/nodenv/nodenv
$ brew install nodenv $ eval "$(nodenv init -)"
このrepositoryで利用するversionをインストールする(作成時点でCDKでの動作確認済み最新バージョンが16.3.0)。
$ nodenv install 16.3.0
ローカルで利用するnodeのバージョンを指定する。
$ nodenv local 16.3.0
ターミナルを閉じるとnodeが見えなくなるため、PATHを通す。 cdkコマンドはlocalのnode_modulesのbinを参照させたいので、相対パスの形でPATHを通す。
- bashの場合
$ echo 'export PATH="$HOME/.nodenv/bin:$PATH"' >> ~/.bash_profile` $ echo 'eval "$(nodenv init -)"' >> ~/.bash_profile` $ echo 'export PATH="$PATH:./node_modules/.bin"' >> ~/.bash_profile`
動作確認
$ node -v v16.3.0
$ npm -v 7.15.1
参考
https://qiita.com/282Haniwa/items/a764cf7ef03939e4cbb1
2. CDKのインストール
cdk initでプロジェクトを初期化するので、一旦cdkはグローバルにインストールする。
$ nodenv global 16.3.0 $ npm install -g aws-cdk $ nodenv rehash $ cdk init app --language=typescript
cdk init app --language=typescriptで初期化が終わったら、globalにインストールしたcdkを削除。
$ npm uninstall -g aws-cdk
$ node rehash
その後改めてaws-cdkをローカルにインストール
$ npm install aws-cdk
3. sam-beta-cdkのインストール
以下のコマンドでインストール。
$ brew install aws-sam-cli-beta-cdk
4. ESLint, Prettierの設定
Typescriptで開発するので、ESLintとPrettierを入れる。 VSCodeを使っているので、VSCode側からESLintとPrettierを使えるようextentionも入れる。
※ Prettirのextensionは、ローカルにPrettierがなかった場合、extensionにbundleされているものが使われるとのこと
Should prettier not be installed locally with your project's dependencies or globally on the machine, the version of prettier that is bundled with the extension will be used.
$ npm install -D eslint @typescript-eslint/parser @typescript-eslint/eslint-plugin $ npm install -D prettier
https://zenn.dev/teppeis/articles/2021-02-eslint-prettier-vscode https://takeken1.hatenablog.com/entry/2020/12/25/005441
ソースの整形はPrettierに任せたほうがよいとのことなので、競合する部分ではESLintの設定をDisableにする。
これをするのに eslint-config-prettier が必要なため、npm でインストール。
$ npm install -D eslint-config-prettier
インストールが完了したらnpx eslint --initを実行して.eslintrc.js を作る。
.eslintrc.jsのextendsの最後にprettierを追加する。extendsへの追記はprettierだけでよいとのこと。
https://github.com/prettier/eslint-config-prettier/blob/main/CHANGELOG.md#version-800-2021-02-21
Prettierの設定ファイルとして
- .prettierrc.js
- .prettierignore
を作る
一応CLIでも操作できるようにpackage.jsonにコマンドを追加。
コマンドは上記のteppeisさんの記事を参考に。
設定ファイルはcommitしているので、ここではESLintとPrettierをインストールするだけ。
5. rubocopの設定
lambdaをrubyで書くので、linterとしてrubocopをインストールする。
$ bundle init
作成されたGemfileにrubocopの設定を追加。
group :development do gem 'rubocop', require: false end
gemのinstall。
bundle install --path vendor/bundle
vendorは.gitignoreに追加しておく。
VSCodeのplugin、ruby-rubocopをインストール。
設定をplouginの設定をsetting.jsonに追加し、rubocop自体の設定を.rubocop.ymlに追加。
CDK App
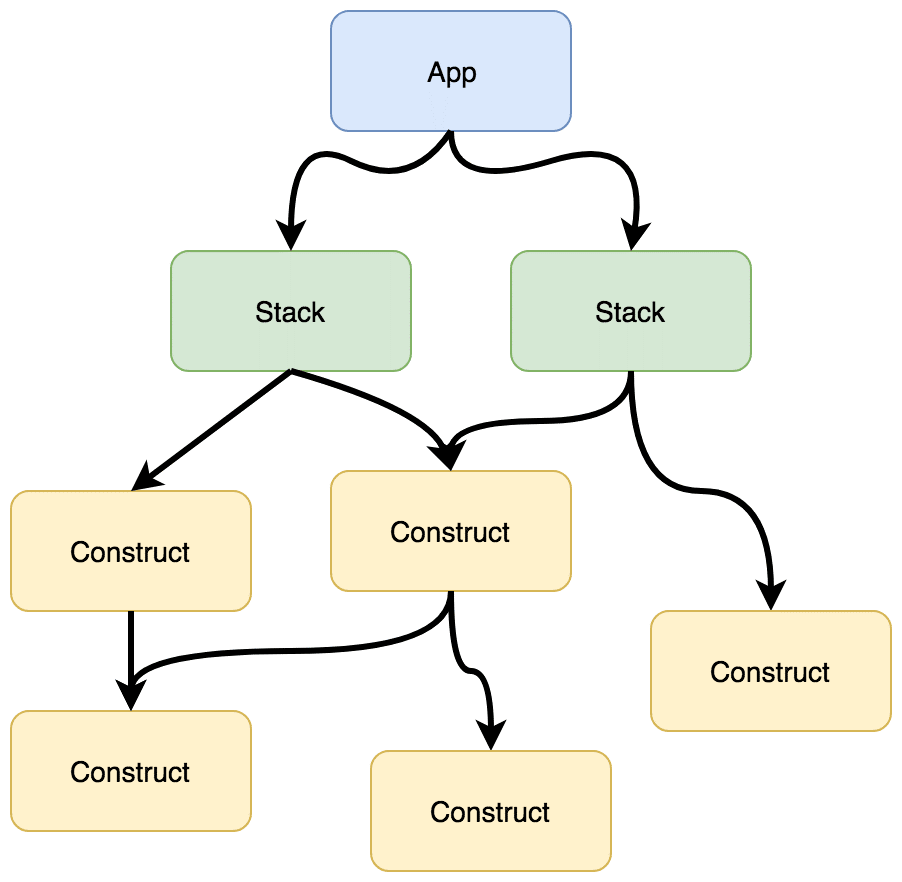
CDKのアプリケーションは、Construct, Stack, Appの3階層で構成される。 Constructが最も基本的な要素で、Constructを組み合わせてStackを作り、Stackを組み合わせてAppを作る要素となる。
https://d2908q01vomqb2.cloudfront.net/da4b9237bacccdf19c0760cab7aec4a8359010b0/2018/12/17/appstack.png https://aws.amazon.com/jp/blogs/aws/boost-your-infrastructure-with-cdk/
{kind=link}
Constructを作るライブラリ(Construct Library)は以下の3つのレイヤーに分類される。
- L1 Construct
- 最も低レベルなConstruct
- Cloudformationのテンプレートと同じ粒度で設定する(Cfnリソースと呼ばれる)
- L2 Construct
- L1よりも高レベルで抽象化されたConstruct
- (推奨とされる)デフォルト値、ボイラプレートなど用いることで、単純に記述量を減らせる
- L3 Construct
- 最も抽象化されたConstruct
- L3 Contruct単体で1つのアプリケーションのようなものを構築することができる(複数のAWSリソース作成される)
https://docs.aws.amazon.com/ja_jp/cdk/v2/guide/home.html
基本的にはL2以上のContruct Libraryを使ってアプリケーションを記述していくのがよい。
Deploy Lifecycle(App Lifecycle)
CDKアプリは上記の図のように、Appを頂点とする木構造になっている。
ディレクトリ構造としては、Appがエントリポイントになるためbin配下に置き、そこから取り込まれる各Stackをlib配下に置く、という形になる。
CDKのdeployは以下の図が示す状態遷移をたどる。
https://docs.aws.amazon.com/ja_jp/cdk/v2/guide/images/Lifecycle.png https://docs.aws.amazon.com/ja_jp/cdk/v2/guide/apps.html
{kind=link}
1. Construction (or Initialization)
- CDKのコードを実行し、定義されているConstructのインスタンス生成及びリンクを行う
2. Preparation
- 最終的な状態を設定する処理で、自動で行われる(開発者は基本的には何もしない)
3. Validation
- 各Construct自身が、Deploy可能な状態であるかどうかを検証する
4. Synthesis
- app.synth()を実行し、各Constructを合成されたCloud Assemblyに変換する
- Cloud Assemblyのschema定義はこちら
5. Deployment
- 生成されたCloud AssemblyをAWS環境にdeployする(=Cloudformationのdeploy)
1〜4のフェーズを経て、CDKのソースコードはdeploy可能なCloud Assemblyに変換される。 そして最後にDeployされる、というサイクルになる。
作成したサンプルアプリ
作成したサンプルではLambdaとApiGatewayを別々のstackにした。 stackをどの単位で分割はいろいろと検討の余地があるが、サンプルなので特に気にせずやっている。
- bin
- cdk_lambda_sample.ts
- lib
- lambda-stack.ts
- apigateway-stack.ts
bin/cdk_lambda_sample.ts
#!/usr/bin/env node import 'source-map-support/register'; import * as cdk from 'aws-cdk-lib'; import { LambdaStack } from '../lib/lambda-stack'; import { ApigatewayStack } from '../lib/apigateway-stack'; const app = new cdk.App(); const lambdaStack = new LambdaStack(app, 'sample-lambda', {}); const apigatewayStack = new ApigatewayStack( app, 'sample-apigateway', lambdaStack.lambdaFunction, {} ); apigatewayStack.addDependency(lambdaStack);
lib/lambda-stack.ts
import { Stack, StackProps } from 'aws-cdk-lib'; import { Construct } from 'constructs'; import * as lambda from 'aws-cdk-lib/aws-lambda'; export class LambdaStack extends Stack { public readonly lambdaFunction: lambda.Function; constructor(scope: Construct, id: string, props?: StackProps) { super(scope, id, props); this.lambdaFunction = new lambda.Function(this, 'SampleHelloHandler', { runtime: lambda.Runtime.RUBY_2_7, code: lambda.Code.fromAsset('lambda'), handler: 'hello.lambda_handler', functionName: 'hello', }); } }
lib/apigateway-stack.ts
import { Stack, StackProps, RemovalPolicy } from 'aws-cdk-lib'; import { Construct } from 'constructs'; import * as apigw from 'aws-cdk-lib/aws-apigateway'; import * as lambda from 'aws-cdk-lib/aws-lambda'; import { LogGroup } from 'aws-cdk-lib/aws-logs'; export class ApigatewayStack extends Stack { constructor( scope: Construct, id: string, lambdaFunction: lambda.Function, props?: StackProps ) { super(scope, id, props); const restApiLogAccessLogGroup = new LogGroup( this, 'SampleRestApiAccessLogGroup', { logGroupName: `/aws/apigateway/hello-cdk-rest-api-access-log`, retention: 1, removalPolicy: RemovalPolicy.DESTROY, } ); new apigw.LambdaRestApi(this, 'SampleEndpoint', { handler: lambdaFunction, deployOptions: { //実行ログの設定 dataTraceEnabled: true, loggingLevel: apigw.MethodLoggingLevel.INFO, //アクセスログの設定 accessLogDestination: new apigw.LogGroupLogDestination( restApiLogAccessLogGroup ), accessLogFormat: apigw.AccessLogFormat.clf(), }, }); } }
Lambaのローカル実行
sam-beta-cdk
ローカルで実行するために、sam-beta-cdkを利用する.
AWS SAM(ServerlessApplicationModel)はLambdaをベースとしたServerlessアプリケーションを作成するフレームワーク.
SAMを操作するためのツールsam-cliでLambdaのローカル実行などができる.
今回利用しているsam-beta-cdkはsamとcdkで作成したリソースを連携させるもの(まだパブリックプレビューの段階). cdkのリソースからsam localのコンテナを作ってローカル実行できるようにするようなものに見えた.
Lambda単体での実行
$ sam-beta-cdk local invoke --project-type CDK sample-lambda/SampleHelloHandler $ sam-beta-cdk local invoke --project-type CDK sample-lambda/SampleHelloHandler Synthesizing CDK App Invoking hello.lambda_handler (ruby2.7) Skip pulling image and use local one: public.ecr.aws/sam/emulation-ruby2.7:rapid-1.29.0.dev202108311500. START RequestId: 657fdd46-ff49-4fa2-bd0d-14e9950b6396 Version: $LATEST END RequestId: 657fdd46-ff49-4fa2-bd0d-14e9950b6396 REPORT RequestId: 657fdd46-ff49-4fa2-bd0d-14e9950b6396 Init Duration: 2.78 ms Duration: 400.00 ms Billed Duration: 500 ms Memory Size: 128 MB Max Memory Used: 128 MB {"statusCode":200,"headers":{"Content-Type":"text/plain"},"body":"Hello, CDK!"}
API Gateway経由
$ sam-beta-cdk local start-api --project-type CDK
このコマンドを実行することでhttp://127.0.0.1:3000/にサーバが起動するが、curlでリクエストを出したところ以下のようなエラーがでる.
Traceback (most recent call last): File "/usr/local/Cellar/aws-sam-cli-beta-cdk/202108311500/libexec/lib/python3.8/site-packages/flask/app.py", line 2447, in wsgi_app response = self.full_dispatch_request() File "/usr/local/Cellar/aws-sam-cli-beta-cdk/202108311500/libexec/lib/python3.8/site-packages/flask/app.py", line 1952, in full_dispatch_request rv = self.handle_user_exception(e) File "/usr/local/Cellar/aws-sam-cli-beta-cdk/202108311500/libexec/lib/python3.8/site-packages/flask/app.py", line 1821, in handle_user_exception reraise(exc_type, exc_value, tb) File "/usr/local/Cellar/aws-sam-cli-beta-cdk/202108311500/libexec/lib/python3.8/site-packages/flask/_compat.py", line 39, in reraise raise value File "/usr/local/Cellar/aws-sam-cli-beta-cdk/202108311500/libexec/lib/python3.8/site-packages/flask/app.py", line 1950, in full_dispatch_request rv = self.dispatch_request() File "/usr/local/Cellar/aws-sam-cli-beta-cdk/202108311500/libexec/lib/python3.8/site-packages/flask/app.py", line 1936, in dispatch_request return self.view_functions[rule.endpoint](**req.view_args) File "/usr/local/Cellar/aws-sam-cli-beta-cdk/202108311500/libexec/lib/python3.8/site-packages/samcli/local/apigw/local_apigw_service.py", line 317, in _request_handler self.lambda_runner.invoke(route.function_name, event, stdout=stdout_stream_writer, stderr=self.stderr) File "/usr/local/Cellar/aws-sam-cli-beta-cdk/202108311500/libexec/lib/python3.8/site-packages/samcli/commands/local/lib/local_lambda.py", line 107, in invoke function = self.provider.get(function_identifier) File "/usr/local/Cellar/aws-sam-cli-beta-cdk/202108311500/libexec/lib/python3.8/site-packages/samcli/lib/providers/sam_function_provider.py", line 74, in get raise ValueError("Function name is required") ValueError: Function name is required
sam-beta-cdkはまだmultistack未対応とのこと. https://github.com/aws/aws-sam-cli/issues/3521#issuecomment-1007239656
また、sam-beta-cdk local start-apiでKeyErrorが発生する場合はcdk.jsonのcontextに"@aws-cdk/core:newStyleStackSynthesis": falseを追加する.
https://github.com/aws/aws-sam-cli/issues/2849#issuecomment-831887699
Deploy
- CDKの初回デプロイ前にはbootstrap処理が必要になるため、以下を実行しておく
$ cdk bootstrap --profile xxxxx
github actionsでCDK deploy
以下のworkflowを設定して、mainへのmerge or pushがあればcdk deployが行われるようにしている.
name: cdk on: push: branches: - main pull_request: jobs: aws_cdk: runs-on: ubuntu-latest steps: - name: Checkout uses: actions/checkout@v2 - name: Setup Node uses: actions/setup-node@v2 with: node-version: '16.3' - name: Setup dependencies run: npm ci - name: Build run: npm run build - name: CDK Diff Check if: contains(github.event_name, 'pull_request') run: npm run cdk:diff env: AWS_DEFAULT_REGION: 'ap-northeast-1' AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }} AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }} - name: CDK Deploy if: contains(github.event_name, 'push') run: npm run cdk:deploy env: AWS_DEFAULT_REGION: 'ap-northeast-1' AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }} AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
以上。
自分用のメモなので、間違っていることがあったらすいません。 気づいたら訂正します。
UnityでVJ用のテンプレートプロジェクト作った
@amagitakayosiさんが公開してくれていたUnityプロジェクトを参考に(すごく参考になりました)、自分が使いやすいように修正を加えてテンプレートプロジェクト作りました。
以下は自分用のメモです。多分すぐ忘れるので。
ざっくり構成

Layer的なものを2つ用意し、どちらかを出力するという形にしています。 個別のサブシーンをレンダリングしたTextureをMixCameraでMixし、続いてEffectCameraでPostEffectをかけ、OutputのところでどちらかのLayerをDisplayに表示するというフローになります。
以下細かい補足
Camera
MixCamera
- Layer0, Layer1用に2つカメラを用意
- 各サブシーンの表示非表示やMix関連の処理を行う
EffectCamera
- Mix処理が終わったテクスチャに対してPostEffectをかける
OutputCamera
- 最終的なOutput用のカメラ
- Layer0 or Layer1のどちらを表示するかを決める
Input
- キーボード、音声、Midiの入力ができる
- このあたりの入力値はグローバルにアクセスできたほうがいいので、安直にシングルトンインスタンに保存
- 入力値自体はMainシーンで受け取って、パラメータインスタンスに保存するようにしている
- 音声入力はLaspを利用
- Midi入力はMinisを利用
- InputSystemを使うので、有効にする必要がある
- ボタンはtoggle的な動作をさせたかったので、個別スクリプトを作ってcolorを変更するようにしている
- built-inのシェーダーを使っているので、build時にエラーがでないように以下の設定を追加
SubScene
- ParameterInitializerの中でシーンをロードするようにしている
- アンロードの機能は実装していないので、重たいシーンが増えてきたりすると辛いかもしれない...
- ControlParameterはサブシーンからでも使えるので、Midiや音声入力もつかえるはず...
おわりに
Unity初学者なので色々と突っ込みどころはあると思いますが、勉強も兼ねて素材作りがんばろう
メモ : History API
Reactを少しいじったときにRoutingでどうなっているだろうと気になって調べた。
React Routerは画面遷移(URLの書き換え)にHistory APIを利用している。
A <Router> that uses the HTML5 history API (pushState, replaceState and the popstate event) to keep your UI in sync with the URL.
historyというpackageでAPIをラップしているっぽい。
History APIはブラウザの履歴情報にアクセスするAPI。
pushStateやreplaceStateの第一引数のstateは、履歴スタックに状態をpushする際に合わせて保存しておきたいものを入れるっぽい。 MDNにはシリアライズできるものなら何でもOKと書いてあるので、ほんとになんでも良さそう。
一応HTMLの仕様も見てみる。 HistoryのInterface。
enum ScrollRestoration { "auto", "manual" };
[Exposed=Window]
interface History {
readonly attribute unsigned long length;
attribute ScrollRestoration scrollRestoration;
readonly attribute any state;
undefined go(optional long delta = 0);
undefined back();
undefined forward();
undefined pushState(any data, DOMString title, optional USVString? url = null);
undefined replaceState(any data, DOMString title, optional USVString? url = null);
};
折角なのでChromiumの実装を見てみる。
blinkの機能のハズなので、このコードがそうだろう。 WebIDLのinterfaceも同じディレクトリにあるし。
void History::pushState(v8::Isolate* isolate,
const ScriptValue& data,
const String& title,
const String& url,
ExceptionState& exception_state) {
WebFrameLoadType load_type = WebFrameLoadType::kStandard;
// Navigations in portal contexts do not create back/forward entries.
if (DomWindow() && DomWindow()->GetFrame()->GetPage()->InsidePortal()) {
DomWindow()->AddConsoleMessage(
MakeGarbageCollected<ConsoleMessage>(
mojom::ConsoleMessageSource::kJavaScript,
mojom::ConsoleMessageLevel::kWarning,
"Use of history.pushState in a portal context "
"is treated as history.replaceState."),
/* discard_duplicates */ true);
load_type = WebFrameLoadType::kReplaceCurrentItem;
}
scoped_refptr<SerializedScriptValue> serialized_data =
SerializedScriptValue::Serialize(isolate, data.V8Value(),
SerializedScriptValue::SerializeOptions(
SerializedScriptValue::kForStorage),
exception_state);
if (exception_state.HadException())
return;
StateObjectAdded(std::move(serialized_data), title, url,
ScrollRestorationInternal(), load_type, exception_state);
}
第一引数のstateはほんとにシリアライズだけ行われているよう。
StateObjectAddedを読んでいくと、DocumentLoader::UpdateForSameDocumentNavigationあたりで履歴スタックを保存しているっぽい。
pushした履歴スタックの復元はHistory::goを見ればわかるかな。
void History::go(ScriptState* script_state,
int delta,
ExceptionState& exception_state) {
if (!DomWindow()) {
exception_state.ThrowSecurityError(
"May not use a History object associated with a Document that is not "
"fully active");
return;
}
DCHECK(IsMainThread());
auto* active_window = LocalDOMWindow::From(script_state);
if (!active_window)
return;
if (!active_window->GetFrame() ||
!active_window->GetFrame()->CanNavigate(*DomWindow()->GetFrame()) ||
!active_window->GetFrame()->IsNavigationAllowed() ||
!DomWindow()->GetFrame()->IsNavigationAllowed()) {
return;
}
if (!DomWindow()->GetFrame()->navigation_rate_limiter().CanProceed())
return;
if (delta) {
if (DomWindow()->GetFrame()->Client()->NavigateBackForward(delta)) {
if (Page* page = DomWindow()->GetFrame()->GetPage())
page->HistoryNavigationVirtualTimePauser().PauseVirtualTime();
}
} else {
// We intentionally call reload() for the current frame if delta is zero.
// Otherwise, navigation happens on the root frame.
// This behavior is designed in the following spec.
// https://html.spec.whatwg.org/C/#dom-history-go
DomWindow()->GetFrame()->Reload(WebFrameLoadType::kReload);
}
}
細かいところは全然わからないが、移動したいページの位置(delta)?があればページを復元して、なければリロードしているっぽい。 復元がされたらpopstateイベントが発生するはずだけど、そのあたりは読めていない。。
AWS Systems Manager / Session Mangerを使う
ブラウザ(マネジメントコンソール)
- EC2に割り当てるIAMロールを作る
- ロールのポリシーには'AmazonSSMManagedInstanceCore'を割り当てる
- EC2に作成したIAMロールを割り当てる
- Systems Manager -> セッションマネージャー -> セッションを開始する -> インスタンを選択してセッションを開始する
AWS CLI
- session manager pluginをインストールする
curl "https://s3.amazonaws.com/session-manager-downloads/plugin/latest/mac/sessionmanager-bundle.zip" -o "/tmp/sessionmanager-bundle.zip" unzip /tmp/sessionmanager-bundle.zip -d /tmp/ sudo ./sessionmanager-bundle/install -i /usr/local/sessionmanagerplugin -b /usr/local/bin/session-manager-plugin
- 以下のコマンドで接続できる
aws ssm start-session --target InstanceID --profile profile名
SSMを使うための条件
- SSMのエンドポイントにアクセスする必要があるため、パブリックIP及びエンドポイントの名前解決ができる必要がある
- パブリックIPなしでやる場合は、NAT GatewayやらVPCエンドポイントの設定が必要
- https://aws.amazon.com/jp/premiumsupport/knowledge-center/ec2-systems-manager-vpc-endpoints/
参考
https://dev.classmethod.jp/articles/troubleshooting-ssm-session-manager-configuration/
Visual Effect Graphを使えるようにするまでのメモ
手順
必要となるパッケージのインストール
- Visual Effect Graph
Window -> Package Manager -> Visual Effect Graphを検索してInstall
- High Definition RP
Window -> Package Manager -> High Definition RPを検索してInstall
※ HD Render Pipleline Wizardが出たら一応Fixしておく
HDRPの設定
- HDRPアセットを作る
Assets -> Create -> Rendering -> High Definition Render Pipeline Asset で HDRPを作成
- HDRPアセットをプロジェクトのレンダリングパイプラインに設定する
Edit -> Project Settings -> Graphics -> Scriptable Render Pipleline Settingsに先ほど作成したHDRPアセットを設定する
Visual Effect Graphオブジェクトを作る
- Assets -> Create -> Visual Effect GraphでVisual Effect Graphを使えるパーティクルシステムのアセットが追加される
GPUEventを使えるようにする
- Visual Effect Graphを使うにあたってGPUEventは必須だと思うので、有効にする
- Edit -> Prefences -> Visual Effects -> Experimental Operators/Blocks にチェックを入れる
その他
HDRPについて
HDRPがなくてもうごく(Visual Effect Graphが出た当時は必須だったみたいなことをどこかで聞いた...)
参考にさせて頂きました
Bloomさせるとき
Scene SettingsのGame Objectがなくなっているので、BloomみたいなPostEffectをやる場合は
- GameObject -> Global Volume を選択し、GlobalVolumeオブジェクトをつくる
- HierarchyからGlobalVolumeオブジェクトを選択
- InspectorにてVolumeからProfileを新しく作成する
- 新しく作成したProfileを選択し、AddOverrideでBloomを設定
これでBloomのPostEffectが使えるようになる
Algoliaのデバッグ
単なる作業メモ
携わってるシステムがAlgoliaを使って検索しているところがあって、そこでエラーとなるケースがあった。 デバッグする上でもAlgoliaのサーバとの通信内容を確認したかったので、Charlesを使って通信をプロキシすることに。
ローカルの開発環境はdockerなので、コンテナの中にCharlesのルート証明書をインストールして、コンテナ内からAlgoliaサーバへのcurlでのリクエストは通るようになった。
しかしAlgoliaのgemをインストールしたシステムはself signed certificateのエラーが出てプロキシできなかった。
仕方ないのでAlgoliaのgemのソースコードを見ていたところ、独自にルート証明書を持っていた。
これにCharlesのルート証明書を追加したらエラーがでなくなり、無事プロキシできた。
スクラムの相談してみた
スクラムやってての疑問を、著名なスクラムマスターの方に質問出来る機会がありました。 聞いた内容をメモに残しときます。
漠然と感じていること
スクラムってこんなんでいいんだっけ?
PJによってやり方はバラバラ。成果出ているなら今のやり方で継続してみよう
スクラムが凄くうまく回ってくるとどいうポジティブな作用がでてくるのだろうか?(チーム/プロダクト)
信頼関係ができ、それによるポジティブな作用が生まれてくる。例えば、
- KPTのKEEPが相互感謝の嵐になる
- 開発メンバーの意識が変わる。プロダクトの品質を自分ごととして考えられるようになる
スクラムイベントのファシリテートぐらいしかやってないけどいいんですかね?
ファシリーテートぐらいしかやってないよw
スクラムイベントに関連する物事のやり方
バックログアイテムの見積もり
全員でざっくりポイントを出して、外れ値の人の意見を聞く。でもう一回ポイントを出す。3回ぐらいやってばらつきがあるなら、多いポイントを採用する。 アイテムのスコープの確認になることが多い。
プランニングで決まったタスクのアサイン
自主性にまかせている。自分ごとにさせていくことが大事。
終わらなかったアイテムは、残作業を再見積もりするか?
しない。2スプリント分の平均をとればベロシティは均一になる。
ベロシティ的なものの振り返りってどうやるのが良い?
実はあまりやっていない。1スプリントの平均値はメンバー全員が認識しているので、その範囲に内でプランニングをし、100%やりきることが大事。 常に同じベロシティを出すのではなく、頑張ったスプリントのあとは多少緩めのプラニングをするなど、メリハリをつけていくことも重要。
KPTにカードがいつまでも残ってしまう問題
消すことが大事。例として、Keep, Problem, Tryを各2列用意して、残したいものを移動し、移動されなかったものは削除していた。 そしてTryの中から次のスプリントでやることを決め、それだを振り返るようにしていた。
KPT(というか振り返り)の結果を生産性の向上に繋げられているかがわからない
メンバーが抱える課題感を吐き出す場としても大切なので、継続していこう
スプリントレビューが実施できていない
スクラムイベントがどれか一つでも抜けていたらそれはスクラムではない。ただ、いきなりレビューするといって集まっても大変なので、
- 常にインクリメント確認できる状態
- インクリメントに対していつでもフィードバックを追加できるもの(スプレッドシートとかでもOK)
を用意しておき、スプリントレビューはそのフィードバックを中心に書くj人するのがよい
今後の改善として、まずはどこから始めるのが一般的なのだろうか
振り返りが大事と一般的にはいわれるが、プランニングでコミットした内容を達成する確率を上げていくことが大事。
大変参考になりました。